LLM Router Architecture: From Distributed Systems Patterns to a Production Circuit Breaker in Redis
Published: 2026-06-23(Last updated: 2026-06-24)
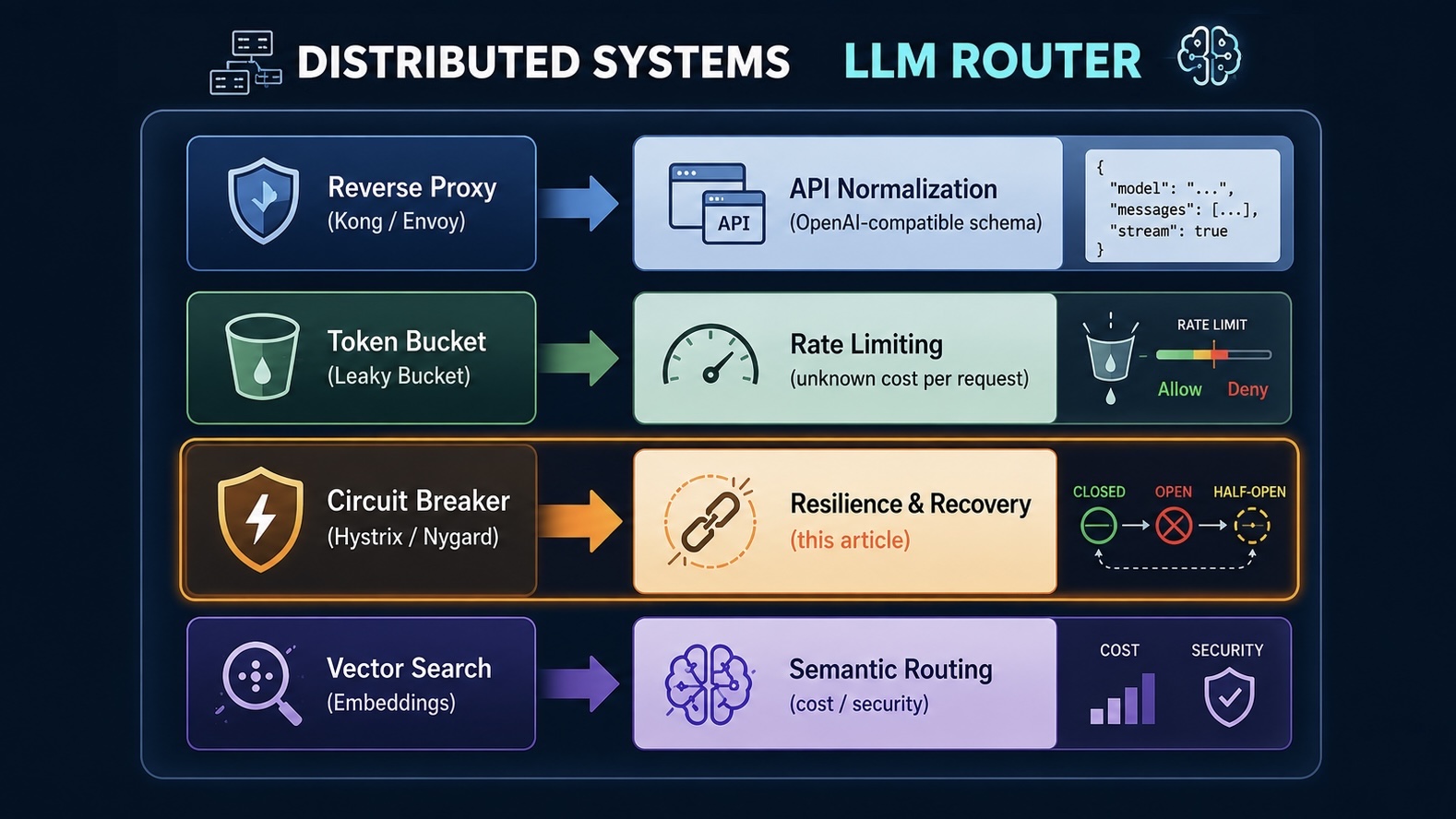
I recently spent some time digging into LLM Routers and AI Gateways. What stood out was how much of their architecture borrows directly from distributed systems patterns. That connection isn’t new — it’s been written about before. What I wanted to do here is go one level deeper: pick one piece of it, the Circuit Breaker, and follow it all the way through to a working implementation.
What an LLM Router actually is
When I first looked at LLM Routers, my mental model was something like “a convenient wrapper around multiple LLM providers.” Once I broke it down, though, the real shape of it turned out to be an AI-native evolution of the Layer 7 (application-layer) load balancer / reverse proxy. Think of it as the traffic-control paradigm that NGINX and Envoy have handled for years, rebuilt to fit a payload — the LLM request — that’s non-linear and unpredictable.
Mapping it to existing distributed systems patterns
Break an LLM Router down into its core functions, and four map cleanly onto established distributed-systems patterns.
1. API normalization and protocol translation (Reverse Proxy)
The equivalent here is what API gateways like Kong or Envoy already do — gRPC ↔ REST, XML ↔ JSON translation. For an LLM Router, this means converting each provider’s distinct API shape (Gemini, Anthropic, Cohere, and so on) into the de facto industry standard: an OpenAI-compatible schema, in real time.
2. Throttling and rate limiting
The equivalent is Token Bucket / Leaky Bucket. But there’s an LLM-specific wrinkle. A normal API can assume “one request = one unit consumed.” An LLM request is “one request = an unknown number of tokens consumed” — you don’t know the real cost until the response comes back. How to close that gap is what the later sections dig into.
3. Resilience and recovery (Circuit Breaker)
The equivalent is the Circuit Breaker pattern from microservices — first described by Michael Nygard in Release It! (2007), then brought to microservices architecture by Netflix’s Hystrix (2012). On detecting a 429 (rate limited) or 503 (unavailable), the router temporarily cuts off the failing provider, then after a cooldown period uses “the next real request” (what this article will later call the probe) to check whether it has recovered. This article is entirely about how this pattern combines with the Token Bucket above.
4. Semantic routing
This replaces traditional path-matching or regex-based branching with routing based on semantic distance — how close a prompt is to some reference point in vector space. It shows up in two places: cost optimization (route simple tasks to a lighter model) and security (detect prompt injection attempts).
This is a well-established field in its own right (vector search, embeddings) and would be worth a post by itself. But it’s hard to verify deterministically, so it’s out of scope for this article.
The full picture: a multi-layer defense pipeline
Put these together, and a production-grade AI backend tends to look like a multi-layer pipeline:

Scope note: This article focuses on Layer 4 — specifically, how Circuit Breaker and Token Bucket integrate. Layers 2 and 3 (semantic cache and cost router) both depend on semantic routing, which warrants its own post.
The next section covers why I picked Circuit Breaker out of the four.
Why Circuit Breaker
Of the four patterns, why dig into Circuit Breaker specifically? It came down to something that kept nagging at me while I was reading about it.
Most LLM Router write-ups explain Circuit Breaker up to the point of “once it’s Half-Open, the next request checks whether the provider has recovered.” What they don’t get into is what “the next request” actually means once you try to implement it.
Two things specifically didn’t sit right.
1. “The next request” can arrive more than once, at the same time
In production, the moment a Circuit Breaker’s cooldown ends, it’s entirely plausible that multiple requests hit the same provider simultaneously. Half-Open is supposed to mean “try exactly one.” Without any safeguard, every request waiting at that moment assumes it’s the one probe and fires off at once — which, if the provider genuinely hasn’t recovered yet, just multiplies the load on something already struggling.
2. Circuit Breaker and Token Bucket look similar, but they’re different mechanisms
In an LLM Router, Circuit Breaker (“is the provider broken?”) and rate limiting / Token Bucket (“do I still have budget left?”) are two different concerns — but it’s easy to see how they’d end up sharing one failure counter if implemented carelessly.1 When that happens, a request that fails only because your own budget ran out gets miscounted as “the provider is down,” and you end up tripping the breaker on a perfectly healthy provider.
The first issue — concurrent probes — doesn’t really come up in what I read; most pieces stop at “Half-Open retries once it’s recovered” and never get into what happens when more than one request hits that moment at once. The second issue isn’t unknown — it’s the kind of thing experienced teams know to watch for2 — but the specifics are easy to miss until you’re actually writing the integration code yourself. That’s why this article isn’t about Circuit Breaker on its own — it’s about getting the combination of Circuit Breaker and Token Bucket right.
The next section works through issue #2 first (the budget/breaker mix-up), then comes back to issue #1 (concurrent probes).
Integrating Circuit Breaker and Token Bucket
The shape of budget management
In an LLM Router, “budget management” boils down to a two-phase process: Reserve (claim an estimated amount up front) and Reconcile (settle the difference once the real cost is known). It’s close to an expense report — submit an estimate, then true it up once the receipt comes in.
Two parties sit on either side of this:
- The local side (your own router): decides “I should still have budget left” based only on its own record of past requests.
- The provider side (the API itself): holds the actual, authoritative state. Only the provider knows the real, current usage against your API key.
If both sides always agreed, this would be trivial. They don’t.
Why local budget tracking is structurally approximate
The local side’s judgment is, at best, an estimate inferred from its own request history. There are several reasons it can drift: another process sharing the same API key, a billing-cycle boundary that doesn’t line up with your local clock, a tokenizer used for estimation that doesn’t exactly match the provider’s real accounting.
When that estimate drifts, this happens: locally, you decide you still have budget and send the request — but the provider has already hit its limit, and you get a 429 back. In other words, passing the local check doesn’t guarantee the server will accept it. This isn’t an edge case; it’s an unavoidable consequence of the local model being an approximation in the first place.
How this gap should feed back into Circuit Breaker
This raises a question: when that 429 comes back, was it because your budget ran out, or because the provider itself is overloaded and rejecting everyone? Which is it?
Honestly, you can’t reliably tell the two apart from the response alone — many providers return the same 429 for both.
So the design I went with here is to skip the root-cause question and treat “a 429 came back” as the only signal that matters. Rather than building out classification logic, I treat it as confirmed evidence that the local model has drifted from reality: force the local bucket to zero and feed it into the Circuit Breaker’s failure tracking. That avoids the cost of building a root-cause classifier while keeping the safe-side behavior: once a drift is confirmed, back off from this provider for a while.
This has a real limit, though. If a provider’s response headers include something like Retry-After or X-RateLimit-Remaining, overwriting the local bucket with that value directly is more accurate than guessing. I haven’t implemented that here — it’s the natural next improvement if you want more precision.
A separate problem in Half-Open: probe single-flight
That covers the budget side. There’s a second, unrelated problem inside Circuit Breaker itself — the one mentioned earlier: multiple requests racing to claim the probe slot the instant a cooldown ends.
This is independent of the budget mismatch above, so it needs a different fix. The ADMIT script in the next section handles both of these — the budget drift and the concurrent-probe problem — but through two separate mechanisms.
Implementation: the ADMIT / REPORT scripts
Why Lua
A naive implementation looks like this:
read remaining balance (GET)
check if it's enough
if so, decrement it (SET)This splits read, check, and write into three separate steps. If two requests land in between those steps, you get overcommitment — pulling more tokens than actually exist. Redis runs single-threaded, so bundling those three steps into one Lua script guarantees nothing else can interleave while it runs. That’s the whole reason for moving multi-step checks into Lua. Redis also has MULTI/EXEC (queue up several commands, then run them all atomically) — but it can’t branch on a value it just read. Once “what to write” depends on “what we just read,” Lua is the right tool.
Script 1: ADMIT — should this request go through?
This script does three things in a single atomic call:
- Checks the Circuit Breaker state (CLOSED / OPEN / HALF_OPEN).
- If OPEN and the cooldown has elapsed, attempts the transition to HALF_OPEN and claims the probe slot.
- Checks the Token Bucket balance and, if sufficient, reserves the estimated tokens.
local circuit_key = KEYS[1]
local bucket_key = KEYS[2]
local now = tonumber(ARGV[1])
local cooldown_ms = tonumber(ARGV[2])
local probe_lock_ttl_ms = tonumber(ARGV[3])
local capacity = tonumber(ARGV[4])
local refill_rate = tonumber(ARGV[5])
local estimated = tonumber(ARGV[6])
local reservation_id = ARGV[7]
local reservation_ttl = ARGV[8]
local state = redis.call('HGET', circuit_key, 'state') or 'CLOSED'
local opened_at = tonumber(redis.call('HGET', circuit_key, 'opened_at')) or 0
local probe_in_flight = redis.call('HGET', circuit_key, 'probe_in_flight') or '0'
local probe_claimed_at = tonumber(redis.call('HGET', circuit_key, 'probe_claimed_at')) or 0
local is_probe = false
-- Breaker check
if state == 'OPEN' then
if (now - opened_at) < cooldown_ms then
return {0, 'BREAKER_OPEN', 0}
end
if probe_in_flight == '1' and (now - probe_claimed_at) < probe_lock_ttl_ms then
return {0, 'PROBE_IN_PROGRESS', 0}
end
redis.call('HSET', circuit_key, 'state', 'HALF_OPEN', 'probe_in_flight', '1', 'probe_claimed_at', now)
is_probe = true
elseif state == 'HALF_OPEN' then
if probe_in_flight == '1' and (now - probe_claimed_at) < probe_lock_ttl_ms then
return {0, 'HALF_OPEN_WAIT', 0}
end
redis.call('HSET', circuit_key, 'probe_in_flight', '1', 'probe_claimed_at', now)
is_probe = true
end
-- Reserve (token bucket, lazy refill)
local tokens = tonumber(redis.call('HGET', bucket_key, 'tokens')) or capacity
local last = tonumber(redis.call('HGET', bucket_key, 'last_refill')) or now
local elapsed = now - last
tokens = math.min(capacity, tokens + elapsed * refill_rate)
if tokens < estimated then
redis.call('HSET', bucket_key, 'tokens', tokens, 'last_refill', now)
if is_probe then
redis.call('HSET', circuit_key, 'state', 'OPEN', 'probe_in_flight', '0')
end
return {0, 'INSUFFICIENT_TOKENS', 0}
end
tokens = tokens - estimated
redis.call('HSET', bucket_key, 'tokens', tokens, 'last_refill', now)
redis.call('SET', 'reservation:' .. reservation_id,
estimated .. ':' .. (is_probe and '1' or '0'),
'PX', reservation_ttl)
return {1, reservation_id, is_probe and 1 or 0}There are two things worth calling out here.
The probe_in_flight flag resolves who gets to probe. Even if multiple requests notice the cooldown has ended at the same moment, this flag means: “if it’s not set, I set it, and I become the probe.” Exactly one request ends up winning. This is the same idea as a distributed lock built on SETNX.
That alone creates a new problem, though: what if the request that claimed the probe slot crashes afterward? The cleanup step (REPORT, below) never runs, probe_in_flight never clears, and the system gets stuck believing a probe is permanently in flight. That’s what orphan recovery handles. probe_claimed_at records a timestamp, and once probe_lock_ttl_ms has elapsed, the old probe claim is treated as stale and a new request is allowed to take over. The elseif state == 'HALF_OPEN' branch in the script above is exactly where this staleness check happens.
Once a reservation succeeds, it stores the estimated token count and whether this was a probe in a reservation:{id} key with a TTL. That TTL is the safety net in case REPORT is never called.
Script 2: REPORT — feeding the real outcome back
After the actual API call returns, a second script reflects that outcome back into the bucket and the breaker state.
local circuit_key = KEYS[1]
local bucket_key = KEYS[2]
local reservation_id = ARGV[1]
local success = ARGV[2] == '1'
local actual_tokens = tonumber(ARGV[3]) or 0
local is_rate_limit_err = ARGV[4] == '1'
local failure_threshold = tonumber(ARGV[5])
local now = tonumber(ARGV[6])
local capacity = tonumber(ARGV[7])
local reservation_key = 'reservation:' .. reservation_id
local raw = redis.call('GET', reservation_key)
if not raw then
return {0, 'RESERVATION_EXPIRED'}
end
local sep = string.find(raw, ':')
local estimated = tonumber(string.sub(raw, 1, sep - 1))
local is_probe = string.sub(raw, sep + 1) == '1'
redis.call('DEL', reservation_key)
if success then
local delta = estimated - actual_tokens
local tokens = tonumber(redis.call('HGET', bucket_key, 'tokens')) or capacity
tokens = math.min(capacity, tokens + delta)
redis.call('HSET', bucket_key, 'tokens', tokens)
redis.call('HSET', circuit_key, 'state', 'CLOSED', 'failure_count', 0, 'probe_in_flight', '0')
return {1, 'OK'}
end
if is_rate_limit_err then
redis.call('HSET', bucket_key, 'tokens', 0)
end
if is_probe then
redis.call('HSET', circuit_key, 'state', 'OPEN', 'opened_at', now, 'probe_in_flight', '0')
else
local failure_count = redis.call('HINCRBY', circuit_key, 'failure_count', 1)
if failure_count >= failure_threshold then
redis.call('HSET', circuit_key, 'state', 'OPEN', 'opened_at', now)
end
end
return {1, 'RECORDED'}On success, it reconciles the estimate against the actual usage and unconditionally moves the breaker back to CLOSED. On failure, a 429 forces the bucket to zero; if this was the probe, it goes straight back to OPEN without waiting on the failure threshold. A regular (non-probe) failure just increments the failure counter, tripping the breaker only once the threshold is hit.
Verification: running it against a real local Redis
I didn’t want this to stop at “should work in theory.” So I spun up a real Redis instance and ran the ADMIT/REPORT scripts against it. No LLM was actually called — the part standing in for doActualApiCall() is a plain mock that can be told to succeed, fail, or return a 429 on demand. Since this is purely testing the bookkeeping, no real API key is needed anywhere.
Five scenarios:
Scenario 1: the happy path. Reserve 100 tokens, the actual usage comes back as 80 — confirmed the bucket correctly gets 20 tokens back.
Scenario 2: tripping the breaker after the failure threshold. Five consecutive failures move the breaker from CLOSED to OPEN. Also confirmed that, while OPEN, Reserve itself gets rejected immediately — the call never even reaches the API.
Scenario 3: probe single-flight under Half-Open.
This was the one I most wanted to see. Simulated the moment cooldown ends by firing three requests at once via Promise.all. Result: exactly one won the probe slot; the other two were rejected with HALF_OPEN_WAIT. This is direct confirmation that the “should be atomic” claim actually holds under real concurrent execution.
Scenario 4: a failed probe snaps straight back to OPEN. When the probe request itself fails with a 429, confirmed it goes back to OPEN immediately, without waiting on the failure threshold, and that the bucket gets forced to zero.
Scenario 5: recovering from a crashed probe (orphan recovery).
Simulated a request claiming the probe slot and then “crashing” — never calling REPORT. Confirmed new requests are correctly rejected within probe_lock_ttl_ms, and that once that window passes, a different request can successfully claim a new probe slot.
5 scenarios, 18 assertions, all passing.
While running this, I made a basic arithmetic mistake in my own test expectations for Scenario 1 — nothing sophisticated, just a wrong number: 10000 - 100 (reserve) + 20 (reconcile delta) = 9920 is correct; I’d written 9980. It’s a small thing on its own, but it’s a useful reminder of how this category of system actually breaks in practice: not from flawed reasoning, but from a number being off by a little. A lock TTL set in the wrong unit, a threshold one digit short — these are the kind of mistakes that don’t show up until you’re actually running the thing, and they’re exactly the kind that matter most here. Reasoning about a design on paper doesn’t give you that. Running it does.
There are two ways to follow this verification yourself. One is the code directly — clone the repo, start redis-server, run node test.js, and you’ll get the same result. The other is the demo below: hit “Fire 3 Concurrent Requests” and you can watch the exact behavior from Scenario 3 — three requests in, exactly one wins the probe slot — happen live in the browser.
A few parameters — cooldown, probe lock TTL, the failure threshold — are tuned shorter in the demo than in the test above, just so you don’t have to sit and wait. The logic being exercised is identical.
You can also open the standalone demo here.
A couple of things this didn’t cover
One thing this article didn’t directly touch on: what should happen to the token budget when a request fails for reasons that have nothing to do with rate limits — a timeout, a 500 from the provider, a dropped connection mid-stream?
I looked for an industry standard here and didn’t find one. What I did find is that Azure’s API Management documentation at least names the underlying tension: the real cost of a request often isn’t known until the response comes back, which means the provider has frequently already spent real compute by the time a failure happens.
That’s really the crux of it. Inference isn’t free — when a request fails partway through, someone already paid for the GPU time, win or lose. Whether that cost should land on the provider (refund the tokens) or the caller (keep the charge) is a question worth taking seriously, not just a UX nitpick. From a user’s side, “it failed, so give it back” feels obviously fair. From a provider’s side, the compute was already spent regardless of what the client received — refunding doesn’t undo that cost, it just relocates it.
I don’t have a confident answer here, and I’m skeptical anyone has a fully settled one. A reasonable middle ground probably treats failures differently by cause — refunding on a clear 5xx (the provider’s problem), not refunding on something the client could have caught earlier — but that’s a direction to explore, not a conclusion this article reaches.
Another point worth being precise about: this article is about routing across providers — your own infrastructure deciding between OpenAI, Anthropic, Google, and so on. That’s a different question from what a single provider does inside their own stack — e.g., routing a request to a lighter or heavier internal model before it ever leaves their infrastructure. The underlying idea (classify the request, route to the right amount of compute) is the same; the operational boundary isn’t.3
Closing thoughts
I went back through the architecture of LLM Routers and AI Gateways with a distributed-systems lens. The broad framing — “an LLM Router is an AI-native evolution of an L7 load balancer” — isn’t new; it’s already out there. What I did here was pick one piece of it (Circuit Breaker), work through how it should combine with Token Bucket, and actually run it against a real local Redis instance to check.
Worth being precise about where this sits relative to existing work.
At the design level: keeping Circuit Breaker (failure detection) and Token Bucket (budget tracking) as separate pieces of state, and treating something like a 429 as a uniform failure signal rather than trying to classify its root cause — as far as I could find, this matches an established pattern already present in existing AI Gateways like LiteLLM.
At the implementation level: the two-phase Reserve/Reconcile token accounting, the single-flight mechanism for claiming a Half-Open probe, and the forced bucket depletion on a confirmed 429 — I didn’t find prior art for this specific combination in what I looked at. I took the established pattern, applied it to constraints specific to LLMs (usage isn’t known up front; multiple probes can arrive concurrently), built it from there, and checked it against 5 scenarios and 18 assertions on a real local Redis.
Circuit Breaker for LLM APIs is a focused corner of infrastructure. For anyone building at this layer, the details are where things get interesting — which is why I didn’t stop at the concept — I built it, and actually ran it to check.
Wrap Up
This post started from the observation that LLM Routers map cleanly onto distributed systems patterns, and zoomed into one of them all the way to a working implementation. Semantic routing itself — and the two layers built on top of it (semantic cache, cost router) — each have enough depth to warrant their own post, and I may get to them if the opportunity arises.
The code is on GitHub. The demo is live at circuit-breaker-token-bucket-demo.vercel.app.
Further Reading
-
Circuit breaker pattern — AWS
- I found this article easy to read because it clearly explains the circuit breaker pattern and its high-level architecture, while including a sample AWS-based implementation — all in a compact format.
-
Rate limiting for LLM applications: Why it matters and how to implement it — PortKey
- A well-written overview of rate limiting in the LLM era. The article explores how API design is changing with the rise of LLM applications and discusses challenges that traditional rate limiting models do not fully address, such as token consumption, agent workflows, multi-tenancy, and cost control. It also covers AI gateway architectures and the metrics that teams should monitor in production. Although it does not dive into implementation details (e.g., TPM enforcement with Redis or token bucket algorithms), it is a worthwhile read for engineers who want to understand the architectural and operational aspects of modern AI systems.
-
How we built rate limiting capable of scaling to millions of domains — Cloudflare
- This post is a deep dive into rate limiting design under a very real constraint: using memcache, which does not support atomic transactions. What’s interesting is how the design evolves under constraints — from fixed windows to sliding window approximations — driven by operational reality rather than theory. The value is less in the final algorithm, and more in the engineering journey: each approach breaks, and the system converges toward a practical trade-off. A harder constraint than the one this post deals with, but a great read on how rate-limiting algorithms evolve under real-world pressure.
-
Why Circuit Breaker Recovery Needs Coordination — Tëma Bolshakov
- While doing a final fact-check pass right before publishing this post, I stumbled onto this one almost by accident. It covers the same ground as this article — the thundering herd at recovery time — and then goes a layer deeper into something I didn’t even run into: racing probes that land on different verdicts (one worker decides CLOSED, another decides OPEN, and whichever write happens last wins). It’s a Ruby implementation of Circuit Breaker, but the reasoning transfers directly. The accompanying PR is worth reading too: a reviewer catches a unit mismatch between Redis’s millisecond-based
px4 and a lock timeout configured in seconds — a real-world instance of the same kind of bug I ran into with my own test assertions. Good reminder that this category of problem isn’t unique to my setup.
- While doing a final fact-check pass right before publishing this post, I stumbled onto this one almost by accident. It covers the same ground as this article — the thundering herd at recovery time — and then goes a layer deeper into something I didn’t even run into: racing probes that land on different verdicts (one worker decides CLOSED, another decides OPEN, and whichever write happens last wins). It’s a Ruby implementation of Circuit Breaker, but the reasoning transfers directly. The accompanying PR is worth reading too: a reviewer catches a unit mismatch between Redis’s millisecond-based
Footnotes
-
In LiteLLM’s router, these are separate components in practice —
cooldown_handlers.pyhandles circuit-breaking, while a dedicatedmodel_rate_limit_check.pyenforces RPM/TPM budgets (pinned to v1.89.3). How blurry the line between “my quota” and “provider failure” gets in practice is visible in this open issue, where a 429 gets miscategorized as a connection error and silently skips cooldown entirely. ↩ -
Portkey’s engineering team has written about keeping retries, fallbacks, and circuit breakers distinct, arguing each addresses a different kind of failure. That’s a related but different point — it’s about not collapsing those three into one mechanism. I didn’t find a clear discussion, in what I looked at, of the specific confusion this article starts from: budget exhaustion getting miscounted as provider failure. ↩
-
The OSS/gateway side of this distinction is consistent across the tools I looked at: OpenRouter frames itself as sitting in front of “400+ models across 70+ providers,” and Red Hat’s LLM Semantic Router — despite using a similar embedding-based approach to classify requests — is explicitly built as an Envoy External Processor sitting in front of multiple backend models, not something baked into a single provider’s own stack. ↩
-
pxsets a key’s expiration in milliseconds in Redis (as opposed toex, which uses seconds) — this is the same option used in this article’s ownADMITscript. ↩